
#20 Modular Monolith: Various Ways Of Communication
More and more often I encounter questions about how modules in a modular monolith can communicate with each other. It is high time to take a closer look at this problem.

Communication in a modular monolith can be considered from three different perspectives:
From the outside. It is represented by a user or an external system that calls our modular monolith to execute some action using e.g., HTTP API.
Communication between modular monolith and components. It is represented by the communication between the application represented by the modular monolith and its components, such as the database, external storage (e.g., Azure Storage, AWS S3), etc.
Inter-module communication. It is represented by two or more modules communicating with each other; for example, one module informs another one about a business fact (event) that occurred or directly calls another module to execute some action.
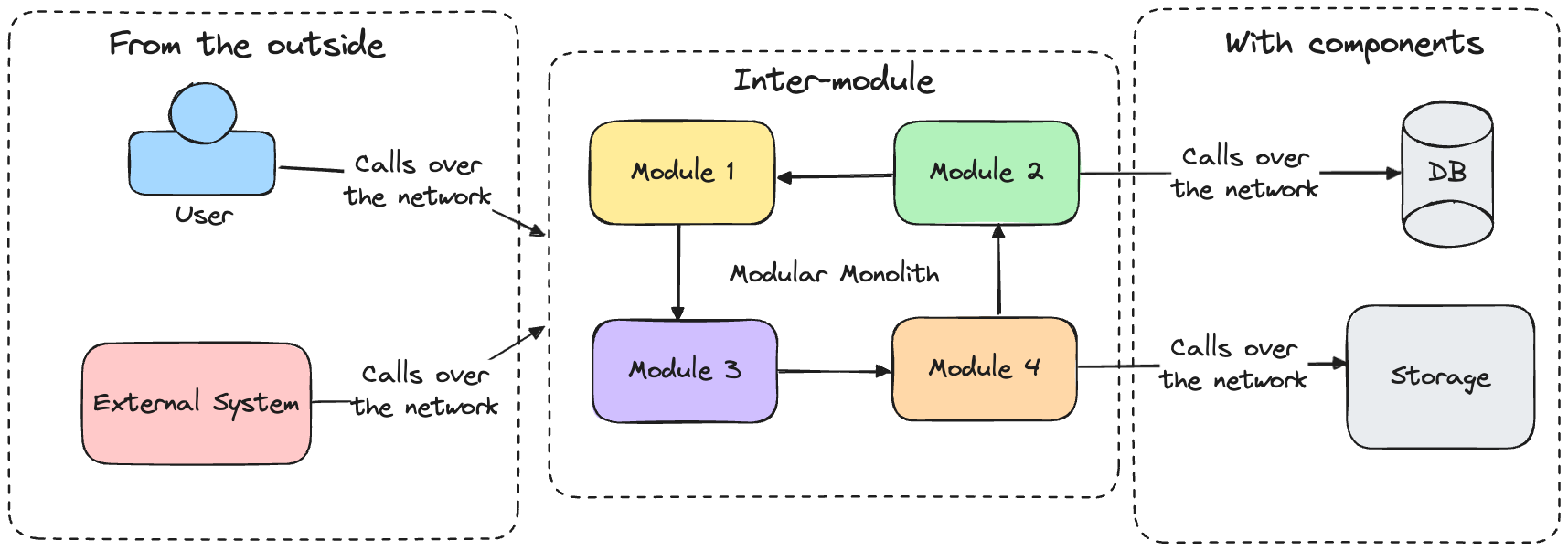
In today’s post, I would like to focus on the last one—inter-module communication. You can find much misleading information about it on the Internet. Also, a lot of questions were asked, and after answering several of them, I decided to document them in one place.
First, let’s have a look at what two basic options we have to communicate between modules:
Direct. One module calls another by reference, contract, or HTTP.
Indirect. One module uses an intermediator to call another through an in-memory queue, message broker, files, database, or gateway.
As all modules in modular monolith run in the same process (single unit), one of the easiest ways to communicate is just to reference the code from another module:

Option 1 (let’s call it this way) creates tight coupling between module 1 and module 2. Module 1 now has full access to all public code from module 2, encouraging its use without much thought. Then, when something changes in the implementation of module 2, it affects the entire operation of module 1. At some point, it will be quite tough to manage all the references between modules. If you need to extract module 2 to a separate deployment unit, decoupling it will require much work. This way of communication usually leads to a big ball of mud.
A state of the application where everything is tightly coupled, duplicated and messy, causing changes in one part to affect multiple others. This makes the application extremely difficult to maintain and evolve.
Option 2 is similar to option 1 because you still need to reference the other module, but it has one limitation. Instead of accessing the entire code, you create the public API of module 2. This public API (don’t confuse it with REST) acts as a facade with the public methods that module 2 allows to be called.
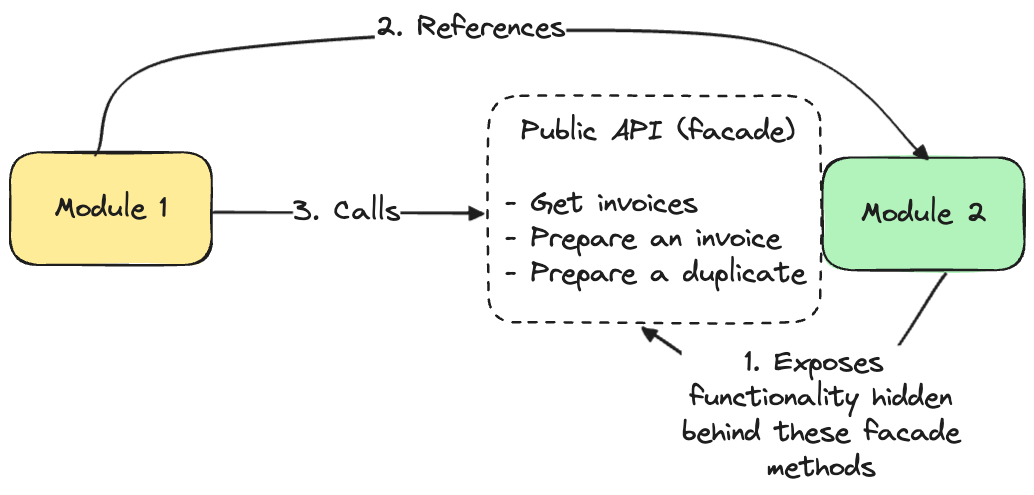
This, of course, still creates tight coupling between both modules, but on the other hand, you are free to change whatever you want in module 2 (besides public API) without the need to change the code in module 1.
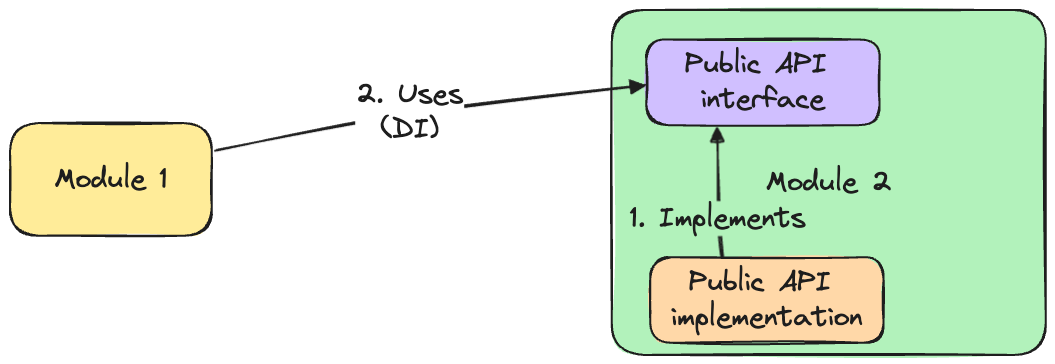
Public API can be designed so there is no direct call to the implementing code. Instead, module 1 can reference the interface defined in module 2, and module 2 will register this interface with the implementation while the entire modular monolith starts.
Another variation is to eliminate direct references to module 2 and move the interface outside to a separate area that contains contracts for module 2 (for example, in C#, this would be another project).
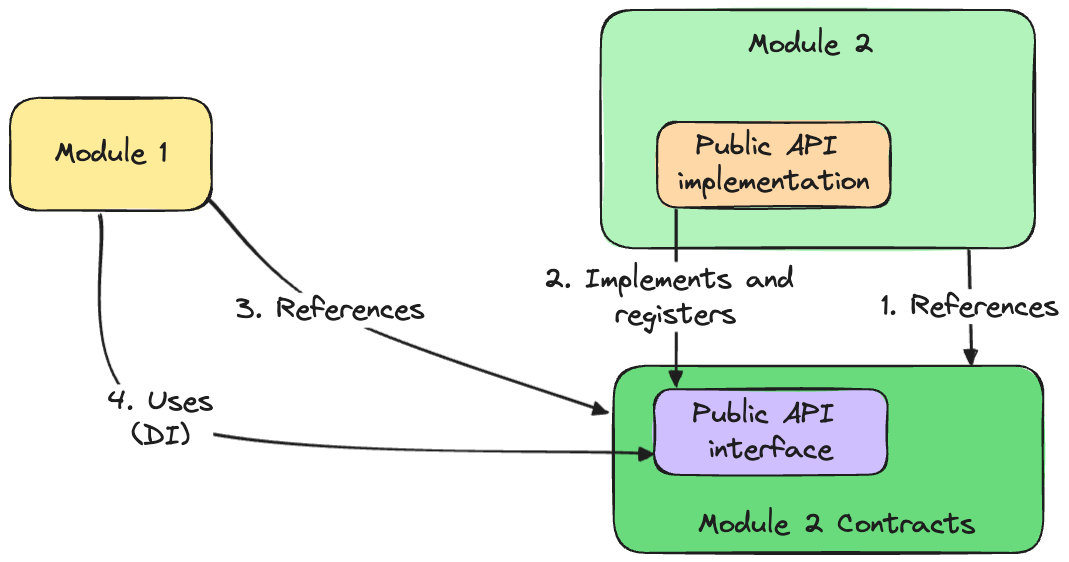
Thanks to such an approach, it is no longer possible to use any implementation from module 2 because there is only a direct reference to the contracts from module 2. This is one of the most common approaches for direct communication.
Next, let's examine option 3 - HTTP calls. Each module has its own endpoints that can be called from the outside by another module using HTTP.

At first glance, this approach seems promising. It reduces tight coupling, replacing it with a more flexible, API-based interaction. However, there's a significant trade-off: you sacrifice the advantage of running the entire codebase in a single process. This advantage is that you don’t need to use network calls. As a result, you don’t need to deal with network failures, partitions, and higher latency - things that are some of the most painful when it comes to distributed systems.
That’s why my recommendation is to avoid network calls in modular monoliths as much as possible.
Of course, there will always be cases where you can’t avoid it. For example, when you decide to go serverless for part of your module (or the entire) just to leverage the power of functions/lambdas. In such a case, there is no other way than using a network call. In fact, it falls into the category of communication between modular monolith and components.
Option 4 is to use a gateway. Instead of referencing another module or its contracts, you can create a gateway to handle communication with a given module. Each module will use this gateway to communicate with module 2.
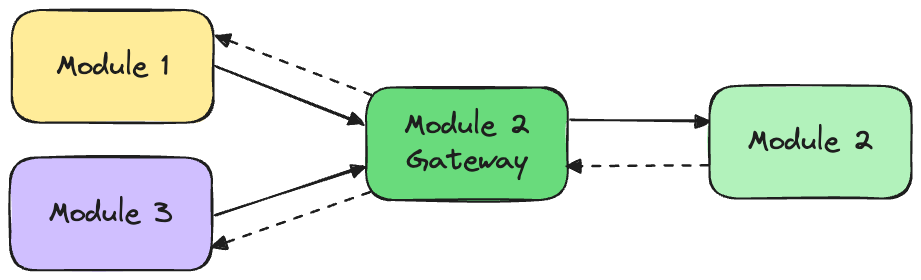
In this setup, no module will directly communicate with module 2.
Next, we come to the world of event-based communication. Instead of using a gateway or directly calling another module, a specific module emits the event describing a business fact that happened, like “Payment accepted" or “Invoice prepared.” Another module reads it and does something with this information, e.g., further processing.
Option 5 is one of the easiest ways to achieve this event-based communication - using an in-memory queue. Yes, you read it right. I know that sometimes it is treated as an anti-pattern, but it is worth considering, especially in the early phases of the application when there is not much traffic. This way, you can speed up the development of a greenfield application.
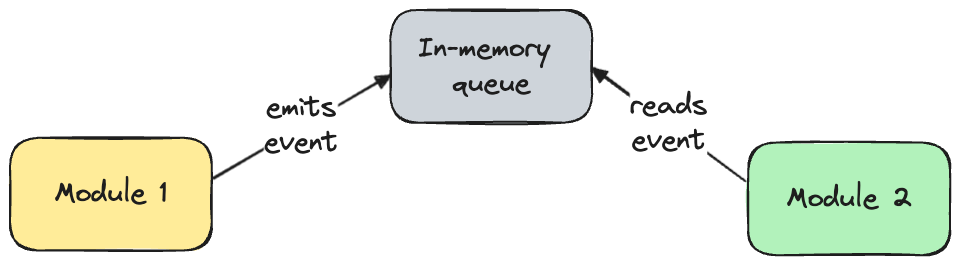
One of the first questions I am asked here is:
What would happen when the event is lost?
Well, there is only one answer—it depends. If your application does not handle large traffic, maybe it is acceptable to fix it by hand. If not, you might consider using outbox and inbox patterns to store and retrieve the information about the event that has to be processed.
Still, you might not be convinced to use the in-memory queue, and that’s fine. That’s where option 6 comes in handy. Here, you replace the in-memory queue with a message broker.
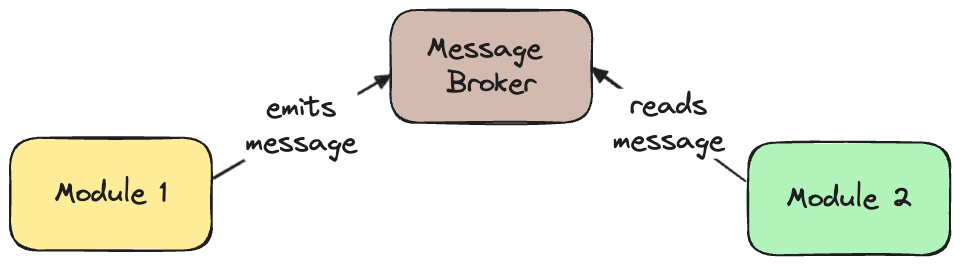
Now, you can have, e.g., three replicas of the message broker, and in case one fails, there are still two operating.
Three is a good number regarding redundancy. In case you need to update/restart one of instances, there are still two. If something happens to one of them, then there is always one operating.
However, there is one major drawback. You need to deal with another external component (message broker) and face network problems (similar story to direct calls using HTTP). The question is if it is worth it. Again, in some cases, yes, while in others, not.
For example, you might observe that one of your modules grows fast and generates a lot of traffic. Because of this module, you have to scale the entire modular monolith. It might be worth considering extracting this module to a separate deployment unit (e.g., microservice) and scaling it only. To avoid having to extract the microservice and introduce the external message broker simultaneously, you can split this work. First, add the message broker, and when you are done, take care of the microservice extraction.
Other options are to use file-based communication (one of the modules stores the information in, e.g., JSON file, and another one reads it), or instead of using a message broker, store the information in the database (similar to outbox and inbox patterns) and then process it using, e.g., background tasks.
I don’t have any one-size-fits-all recommendation, but I would say you should avoid the trap of using ONLY event-based communication in modular monoliths. Leverage the power of running the entire code in a single process, and use event-based communication only where you really need it.
How do you handle the communication in your modular monolith?