
#31 The Parallel Puzzle: Solving Database Changes Across Parallel Versions
Running different versions of an application at the same time can be tricky, but the real headache often comes from the database changes. Even a small change can cause big problems across versions.

In the last post about deployment strategies, I promised I wouldn’t leave the topic of database challenges when we have to support various, parallel application versions. It is the perfect time to face it. I will walk you through several real-world scenarios I have encountered frequently in my past projects.
Before we look at the scenarios, let's first outline the common problems developers face when trying to maintain database compatibility across parallel versions:
Schema evolution. How do you change the database schema without breaking existing application versions?
Data migration. What is the best way to update existing data to meet new schema requirements?
Query compatibility. How do you ensure that older application versions can still effectively query the database after schema changes?
Rollback scenario. What happens and how do you react when you need to rollback the application to the previous version?
With this in mind, you must always prepare the entire migration plan for the change. You know how it goes - someone says, “We will figure it out as we go,” and suddenly you are in hot water. Customers are locked out, nothing works right, and you are sweating bullets. Not fun, right?
To omit such a situation, plan it out, step by step:
What is the first thing you need to change? Get specific.
Then what? And after that? Map it all out.
For each step, have a rollback plan. Think of it as your “undo” button.
Now you have got a game plan in your pocket. Sure, life loves to throw curveballs. Your plan might need to twist and turn a bit - that is normal. But here is the cool part: you are not going in blind. You have thought through the various scenarios before they happen.
Time to get our hands dirty. You know what they say - the proof is in the pudding, or in our case, the database. Three scenarios will help you to understand the impact of the change.
IMPORTANT: Steps in each scenario are presented separately to minimize the risk of errors. While some steps could potentially be combined (e.g., removing unnecessary code alongside dropping a database table), breaking them down offers several advantages:
It reduces the chance of overlooking important details ("Oops, I forgot about this or that").
It allows for more precise tracking of changes.
It simplifies rollback procedures if issues arise.
It makes the change process more manageable and easier to review.
Scenario 1 - Change the column type
A table named Employees stores information like:
FirstName
LastName
Email
HireDate
EmployeeId (numeric, required)
And a few other columns. There is a new requirement—you need to change the type of EmployeeId column from numeric to text because IDs will now include department prefixes.
In the current version of the application (1.0), we both read from and write to the EmployeeId column.

We are ready for the first change (application 1.1). Make the EmployeeId column optional. Next, add a new optional column EmployeeIdWithPrefix to the table next to EmployeeId. The new version will only write to the EmployeeIdWithPrefix column, but will still read from both columns. This way, application 1.0 will continue to read from and write to the EmployeeId column.

Now we have two versions of the application (1.0 & 1.1), both compatible with the new database schema.
The next step requires the migration of all existing entries from the EmployeeId column to the EmployeeIdWithPrefix. Make the EmployeeIdWithPrefix column required and stop reading from the EmployeeId column. Additionally, the entire code related to EmployeeId is dropped.
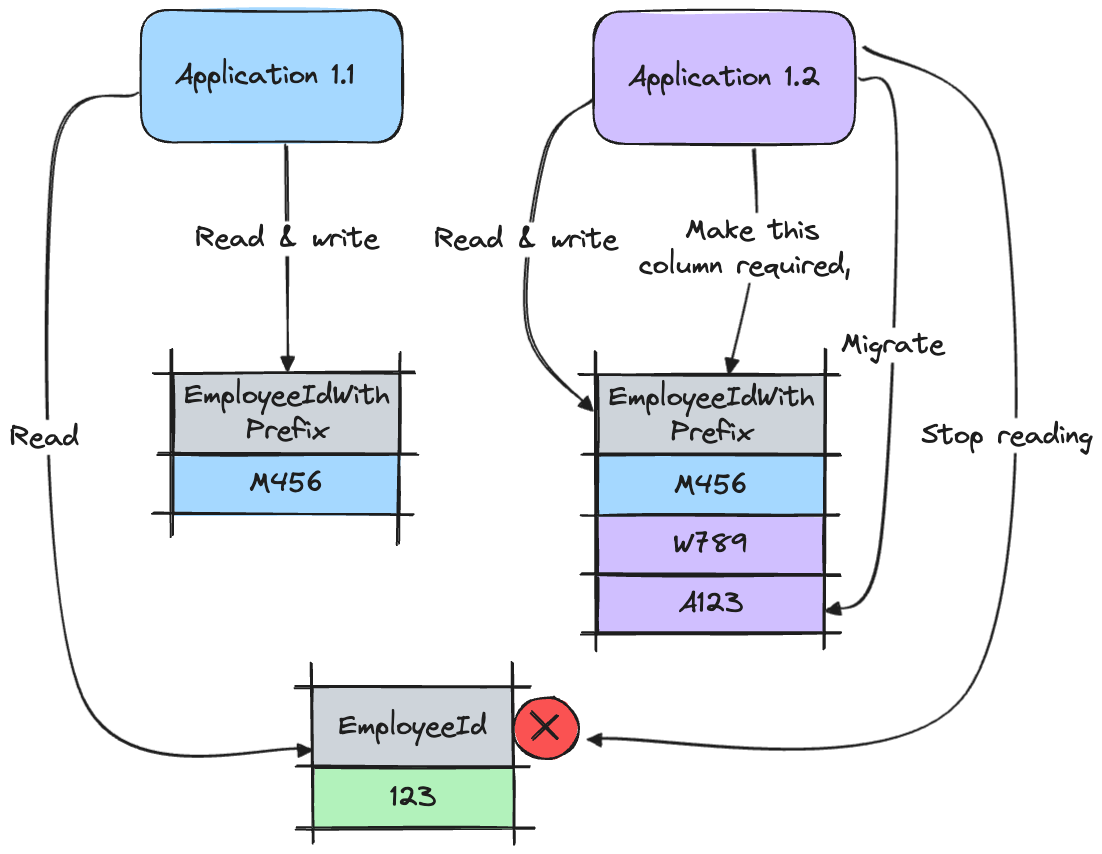
Again, we have two versions of the application (1.1 & 1.2), both compatible with the database schema. In case of problems with application 1.2, we can simply continue with application 1.1.
With version 1.3 we can drop the EmployeeId column. It can be the last step of the migration unless there is a need/will to rename the EmployeeIdWithPrefix to EmployeeId. If so, you can handle it in version 1.4.

Scenario 2 - Move the column to another table
A table named Employees stores information like:
FirstName
LastName
Email
HireDate
Address (required)
And a few other columns. There is a new requirement—you need to move the Address column to another table.
In the current version of the application (1.0), we both read from and write to the Address column inside the Employees table.

We are ready for the first change (application 1.1). Add a new optional Address column to another table (if the table does not exist yet, you have to create one. Can be done in this step as well). Write to and read from both tables.
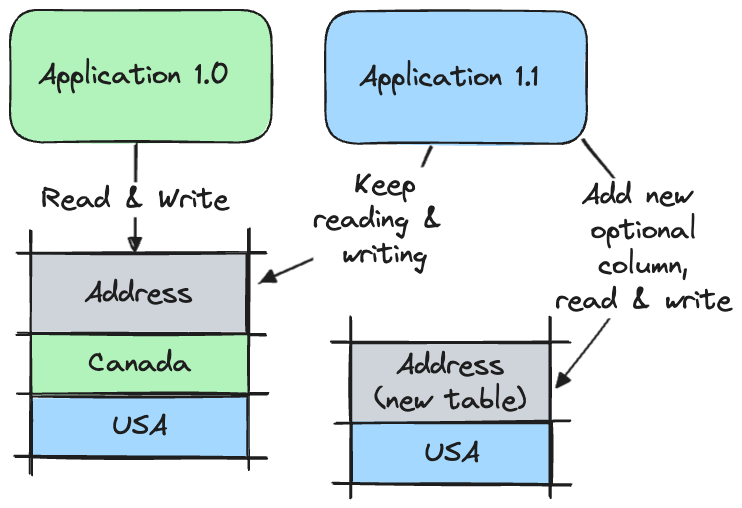
If something goes wrong with application 1.1, you will not lose data stored in a new table because it will be replicated in the old Address column as well.
Next, make the old Address column optional and stop writing to it. Still read from both tables.

In version 1.3, migrate all entries from the old Address column to the new one (you have to take care of duplicates). Make the new Address column required and stop reading from the old one. Ensure that all code related to the old Address column is dropped (we do not need it anymore in version 1.3 as we stop interaction with this column).

The last step is to drop the old Address column in version 1.4.

Scenario 3 - Remove the column
A table named Employees stores information like:
FirstName
LastName
Email
HireDate
And a few other columns. There is a new requirement—you need to drop the HireDate column.

If we do that immediately and release a new version (1.1), then version 1.0 (working in parallel) will stop working because it will still try to access the column that does not exist anymore. That’s why we have to also handle it step by step.
First, make column HireDate optional. Stop writing to it, but continue reading.

Next, remove the code responsible for reading from the HireDate column. Ensure that all code related to the HireDate column is also dropped (we do not need it anymore in version 1.2 as we stop interaction with this column).

Finally, in version 1.3, remove the HireDate column.

More parallel versions
Dealing with more than two versions, like 1.0, 1.1, and 1.2, follows a similar planning process. The main difference is that now three versions need to work with the same database structure. This makes things more complex.
While it is more complicated than managing two versions, the basic idea is the same. Take your time to think through each change and how it impacts all versions.
How do you deal with multiple, parallel versions of your application?
A way to maintain data consistency during the migration phase with both columns or tables could be to use DB triggers, considering your database supports it. I usually do not rely on DB triggers but here it can performs some replication of the data between columns. Alors views can be used to hide actual "physical" schema changes. Some DB systems also provide upgradable views...