
#38 Step One of Evolutionary Architecture: Focus on Simplicity
Let's face it - overcomplicating things is in our DNA as developers. That is exactly why we need to fight it and keep things simple. Want to learn how? Check out our evolutionary steps.

Before we start today’s post, I would like to let you know that my “Master Software Architecture” book is finally available on Amazon as a paperback! You can find it here (you can change the marketplace by switching to .de, .it, .fr in the URL).
Two years ago, Kamil Bączek and I created a repository demonstrating the evolution of a Fitness Studio application. We structured it around four key evolutionary steps we identified.
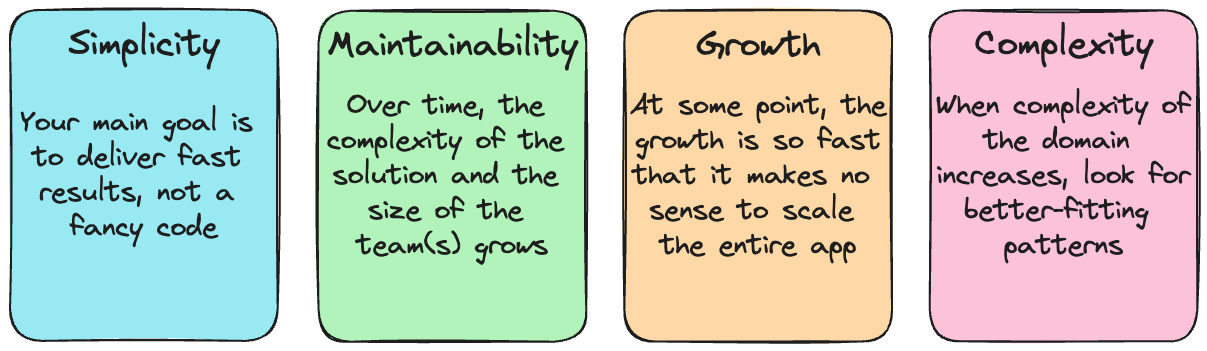
Each step represents a distinct phase in your application's maturity. This series will break down all the steps so you can understand them better.
Today we will focus on the first one - simplicity.
When starting a new app, we often get excited and want to throw in every cool tech we have heard about - Kubernetes, Kafka, Redis, microservices, you name it. And it is natural - we are developers, and we love trying new things!
Here is the thing - we often get caught up copying what big companies like Netflix or Amazon are doing. But that is a trap. Their problems and scale are nothing like what most of us are building. Their systems are solving totally different challenges, dealing with traffic levels our apps may never see.
When we overcomplicate things from the start, we create a mess. Systems end up with too many moving parts talking to each other. New team members struggle to understand what is going on. Bugs become a nightmare to track down. And don't even get me started on the costs - they spiral out of control. All because we let our tech dreams run wild instead of keeping things simple.
You know what is funny? This keeps happening even though we are smart people. So what is the deal? From what I have observed, it is not about being smart - it is about wisdom. And that wisdom? You only get it from years of building different systems and, yeah, screwing up along the way. Those face-palm moments when things go wrong? They are actually our best teachers.
We spend years learning this hard truth: there is no one-size-fits-all architecture that works for everyone. What works depends on your specific situation - your team's skills, your company's setup, and what your business needs. People keep talking about "context" because it really is everything.
Context is king - and they are right.
In this first step - Simplicity - we are not reinventing the wheel. The goal is dead simple: build the most straightforward solution that works right now.
Here is the catch: we should stick to keeping things simple no matter how far along we are. But it is trickiest at the start because that is when we have to make the most decisions. And guess what? That is exactly when we know the least about what we are building and how it will be used.
This problem is known and is called the Project Paradox.

The graph makes perfect sense - by the time we actually understand things well, most of the big decisions are already behind us. Ironic, right?
That is why starting super simple is like a cheat code. We push the big decisions into the future, when we will actually know enough to make smart choices. Instead of guessing early, we learn as we go.
OK, but what does it mean to start simple?
Think about starting with a modular monolith instead of microservices. You dodge all those distributed system headaches - no network failures, no latency issues, no need for retry logic. Everything runs in one process, so modules just talk to each other directly (by reference, gateway, facade) or use events within the in-memory queue.
Yeah, here is a spicy one - consider using initially an in-memory queue instead of something external like RabbitMQ. Sure, you might lose some messages if the system crashes, but maybe that is okay for now. You are trading some reliability for much simpler maintenance. As always, in such cases use your common sense.
Or take databases. Instead of giving each module its own database (physical split), use database schemas (logical split) to keep things separate. So, each module will have its own schema. It is simpler but still keeps your data organized.
Instead of jumping straight to Kubernetes, start with a simple deployment using e.g. Azure App Service, or AWS Elastic Beanstalk. You will spend way less time on infrastructure and can focus on what your app actually needs to do.
Skip the fancy caching system at first. Instead of setting up Redis right away, leverage the power of your database engine to a maximum, or in the simplest scenario use your application’s memory cache (if the application runs on a single instance).
And so on for all areas of your application.
Think of every change like it is coming out of your own pocket - you are paying for the servers, maintenance, all of it. Once you start thinking this way, you will get better at spotting unnecessary complexity. It is like developing a sixth sense for what is really needed versus what is just cool to have.
Trust me, it will change how you look at every decision.
Curious about seeing this in action? Check out our Evolutionary Architecture by Example repository. We also have a Discord channel where you can ask questions and join the discussion.
What do you think about such an approach?