
#43 Oops, I Deployed It Again: Learning from Our Continuous Deployment Fails
While we have managed to make our deployments successful most of the time, there is still that little percentage where human nature kicks in. Learn about the most common mistakes we encountered.

Happy New Year!
Last year, I had the opportunity to speak at several conferences including Devox, Infoshare, .NET Day Switzerland, and DevConf. While I covered various topics, I found myself drawn repeatedly to one of my favorites: continuous deployments.
I still remember my first encounter with this concept. It left me both skeptical and fascinated. Skeptical, because I wasn't used to the idea of fully automating the entire software development cycle - no dedicated testing phases, no manual approvals, just rapid feedback loops. And at the time, every presentation I saw was purely theoretical. It wasn't a widely adopted practice yet, more of an aspirational goal than reality. Whenever I asked speakers about their actual experience with it, the answers were: "Oh, we have tried it in a test environment" or "Just for a hobby project."
Being someone who loves turning theory into practice, I decided to look at this idea at the company I was working for several years ago. To my delight, it was approved, and we made it happen. In the end, everyone was quite happy with the result - customers, the company, and the developers.
That success led me to implement it in more organizations, including one large-scale with complex, established processes (yes, it was possible!). Each implementation brought its own challenges and experiences, teaching me invaluable lessons along the way.
Before going deeper, let's look at some eye-opening data. A study by SlashData and the Continuous Delivery Foundation tracked deployment frequencies across years, and the results might surprise you. Despite what the tech buzz on social media might suggest, the reality is quite different. Think continuous deployment is everywhere? The data tells a different story - only about 10% of surveyed teams deploy multiple times per day.

And you know what? That's perfectly fine. Continuous deployment isn't a one-size-fits-all solution - sometimes it simply doesn't make sense for a particular context, team, or product.
Anyway, coming to the heart of this post. I want to share with you the real mistakes we have been continuously making. Each one has taught us valuable lessons, but here is the honest truth: even after all these years, I can't claim to have found a perfect solution. While we have managed to make our deployments successful 98% of the time, there is still that 2% where human nature kicks in - someone forgets a crucial step, makes an unexpected mistake (yes, myself included!), and things go sideways.
Showing hidden features

Here is a classic pitfall we have run into time and time again: accidentally revealing features that were supposed to stay under wraps until a big marketing event. I can already hear you saying "But feature flags exist, you fool!" And yes, you are absolutely right - they do.
But here is the thing - even with four-eyes checks, about once every 20 or 30 deployments, someone (doesn't matter how experienced they are) forgets to add (or set) that crucial feature flag. And just like that... BANG! A feature that was meant to be unveiled at next month's marketing event is suddenly live for everyone to see.
Simple mistake, painful consequences. :)
Issues while touching a database
Now it is time for a particularly tricky challenge - managing database changes when you are running multiple versions of your application simultaneously (whether through blue-green, rolling, or canary deployments). The complexity here isn't in any specific type of change - it could be adding a column, changing a data type, or migrating data to a new structure. Your challenge lies in orchestrating these changes across parallel versions without breaking anything.
Every database change needs a carefully thought-out plan:
First, map out your entry point - what is the very first change that needs to happen? This could be adding a nullable column or setting up a temporary transition state.
Next, outline each subsequent step in detail, understanding how both old and new versions of your application will interact with the database during each phase.
Finally, develop a rollback strategy for every single step. Think of it as your safety net - you need to know exactly what to do if things go sideways.
Well, even with perfect planning, things can still go wrong during deployment. This is one of those skills that comes with experience. In the beginning, you will likely stub your toe a few times - it is almost a rite of passage. But with each deployment, each mistake, and each recovery, you will build up the knowledge that will help you prevent such issues.
In one of my previous posts, I described this problem in detail (based on a real-world example):
#31 The Parallel Puzzle: Solving Database Changes Across Parallel Versions

In the last post about deployment strategies, I promised I wouldn’t leave the topic of database challenges when we have to support various, parallel application versions. It is the perfect time to face it. I will walk you through several real-world scenarios I have encountered frequently in my past projects.
UI issues that were not caught by automation
One of the best lessons I learned while working with continuous deployments was to accept artifacts that can occur in production. What do I mean by an artifact? For example, we can accept that while the key business process works fine (validated by our automated tests), there is a chance that something minor might not work as expected.
Let me explain.
Imagine that inside your application there is a modal window that is part of a business-critical process. This window contains some kind of a form, and additionally two buttons - one to cancel, and another one to submit.

After one of your CSS changes, someone spots in the production environment that buttons are outside of the modal, floating somewhere around:
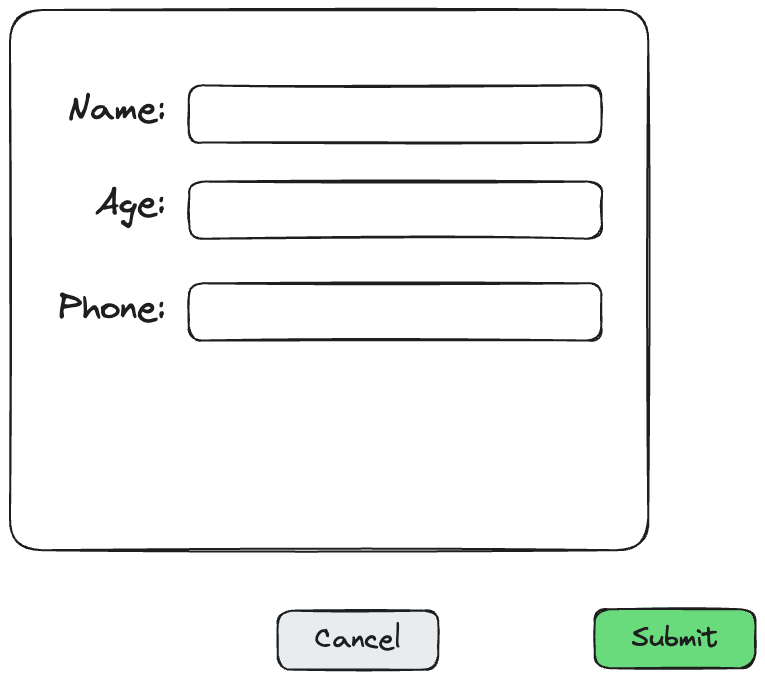
How was that possible? While your automated tests can verify your critical business process perfectly well, they might miss these kinds of visual details. Sure, your tests can confirm that buttons exist, find them, and execute the action, but they won't catch if a button suddenly appears in the wrong spot on the page. It is a blind spot in automation that you need to keep in mind when setting up continuous deployment. But here is the point: you can quickly react and deploy the new version (I prefer it over the rollback, but you can also roll it back) within minutes or hours, thanks to the automation that you have.
Failures caused by updating libs
Library updates are an integral part of development life. Whether they are internal or third-party. The trigger could be anything from needing a new feature to avoiding a security vulnerability. But regardless of why you are updating, it is the aftermath that can give you a real headache.
Take this common scenario. Everything compiles perfectly, all tests pass with green color, but then you hit runtime and... surprise!

It is similar to the modal example earlier - you might update an image library and while your automated tests happily verify that the image tags exist in the HTML, they won't catch that the images themselves are rendering incorrectly.
This is a relatively simple example, but it illustrates a broader point. Good observability tools (looking at you, Sentry!) can help you catch these issues before your users do, but it is still a classic mistake that you need to watch out for.
Summary
Continuous deployment is a powerful practice, but it is important to approach it with eyes wide open. While the examples I have shared might seem discouraging, they are part of the learning process that every team goes through. The key isn't to achieve perfection - it is to learn from each incident and maintain the ability to respond quickly when things go wrong. And remember, what matters most is finding the rhythm that works for your team, your product, and mainly your customers.
If you are interested in a general overview (where these mistakes are one of the topics), feel free to watch a video from one of my talks called “Oops, I deployed it again: a survivor’s guide to continuous deployment”: